Abstract
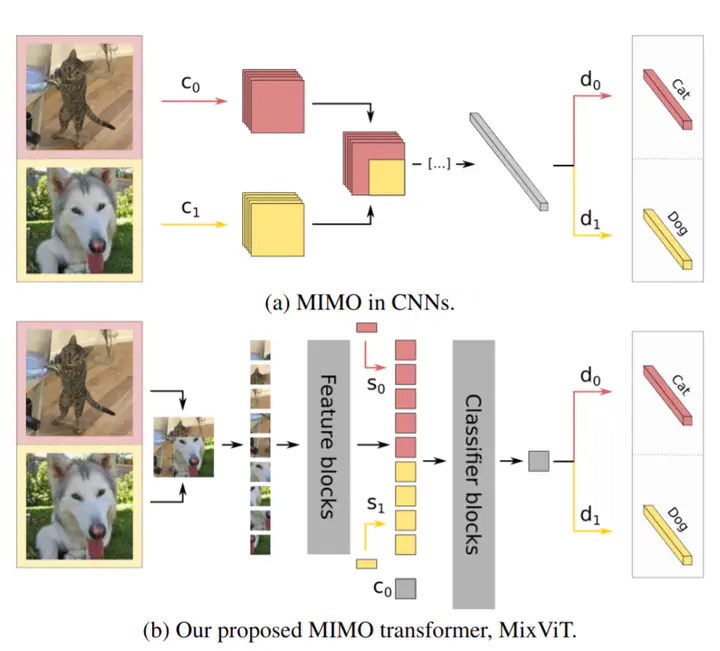
Multi-input multi-output models have proven capable of providing ensembling for free in convolutional neural networks by training independent subnetworks that can be ensembled. How these architectures translate to vision transformer architectures is however unclear. In this paper, we introduce MixViT, the first multi-input multi-output framework for vision transformers. After discussing MixViT and the novel source embedding mechanism it relies on for subnetwork separation, we show how much it improves on standard transformers in a preliminary study on CIFAR100.
The work in this paper was extended in a preprint: “Reconciling feature sharing and multiple predictions with MIMO Vision Transformers”
Remy Sun
Research scientist
I am a research scientist (ISFP) at Inria Sophia Antipolis (MAASAI) team working on the injection of knowledge in neural networks.