Mixing Samples Data Augmentation
Mixing Samples Data Augmentation (MSDA) help regularize models by mixing the contents of multiple images during training.
I believe they provide a good opportunity to teach neural algorithms to reconcile information mixed from different samples so as to better understand the problem:
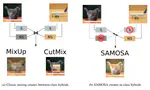
On the one hand, I am interested in mixed samples that only contain the semantic content of one image. As such, I developped a new type of data augmentation (in-class MSDA) that helps model generalize by embedding the semantic content of samples into the non-semantic context of other samples to generate in-class mixed samples. This type of MSDA has particular benefits in low label settings where there is not enough labeled data for models to learn to discard non-semantic information on their own.
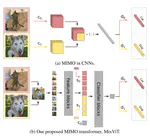
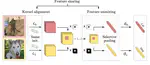
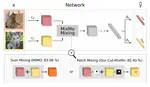
On the other hand, I show input mixing can be used as an input compression method to train multiple subnetworks in a base network from compressed inputs. Indeed, by formalizing the seminal multi-input multi-output (MIMO) framework as a mixing data augmentation and changing the underlying mixing mechanisms, we obtain strong improvements of over standard models and MIMO models. Furthermore, given proper mechanisms, the subnetworks trained by MIMO MSDA can learn very general features by sharing these features.
Remy Sun
Research scientist
I am a research scientist (ISFP) at Inria Sophia Antipolis (MAASAI) team working on the injection of knowledge in neural networks.