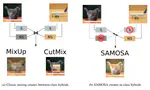
Editing sample contents for data augmentation
While Mixing Samples Data Augmentation (MSDA) offer a powerful tool for regularization, they offer very little control on the content mixed.
I study how manipulating the contents mixed into the final augmented image can improve the training of networks. This is a complex endeavor that requires identifying different types of information, extracting this information, mixing it into a reconstruction framework and finally making use of the new examples.
To illustrate this, I developped a new type of data augmentation (in-class MSDA) that helps model generalize by embedding the semantic content of samples into the non-semantic context of other samples to generate in-class mixed samples. This type of MSDA has particular benefits in low label settings where there is not enough labeled data for models to learn to discard non-semantic information on their own.
Remy Sun
Research scientist
I am a research scientist (ISFP) at Inria Sophia Antipolis (MAASAI) team working on the injection of knowledge in neural networks.